BibTeX
@inproceedings{abootorabi-etal-2025-ask,
title = "Ask in Any Modality: A Comprehensive Survey on Multimodal Retrieval-Augmented Generation",
author = "Abootorabi, Mohammad Mahdi and
Zobeiri, Amirhosein and
Dehghani, Mahdi and
Mohammadkhani, Mohammadali and
Mohammadi, Bardia and
Ghahroodi, Omid and
Baghshah, Mahdieh Soleymani and
Asgari, Ehsaneddin",
editor = "Che, Wanxiang and
Nabende, Joyce and
Shutova, Ekaterina and
Pilehvar, Mohammad Taher",
booktitle = "Findings of the Association for Computational Linguistics: ACL 2025",
month = jul,
year = "2025",
address = "Vienna, Austria",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2025.findings-acl.861/",
doi = "10.18653/v1/2025.findings-acl.861",
pages = "16776--16809",
ISBN = "979-8-89176-256-5",
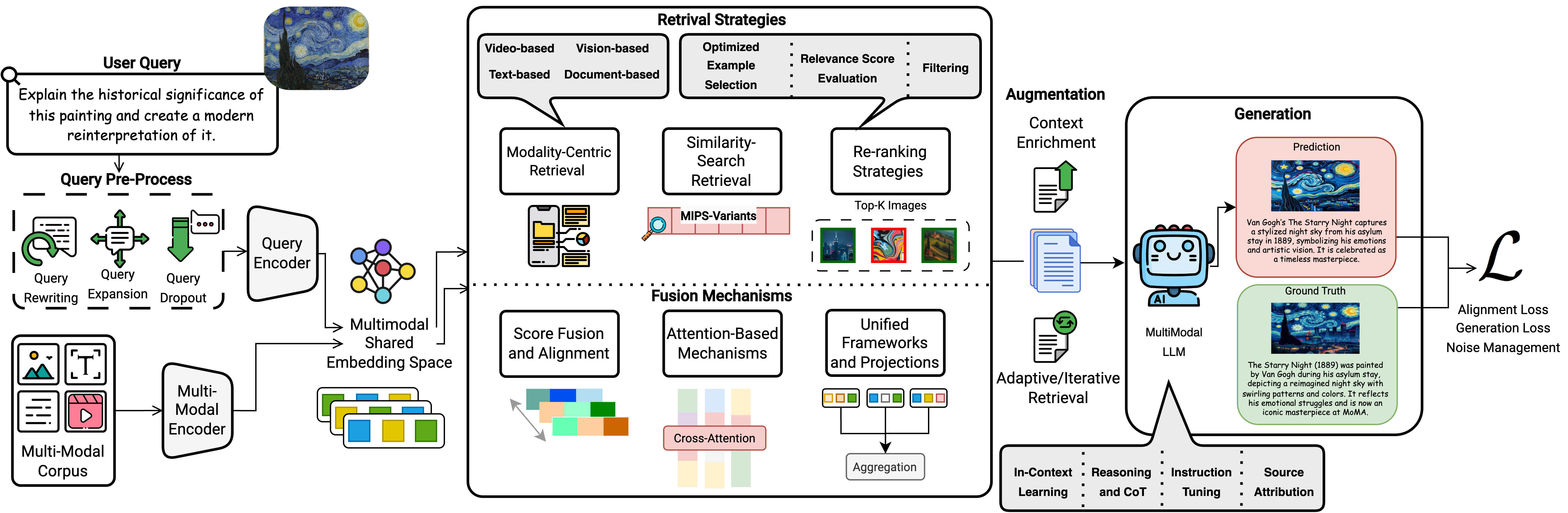
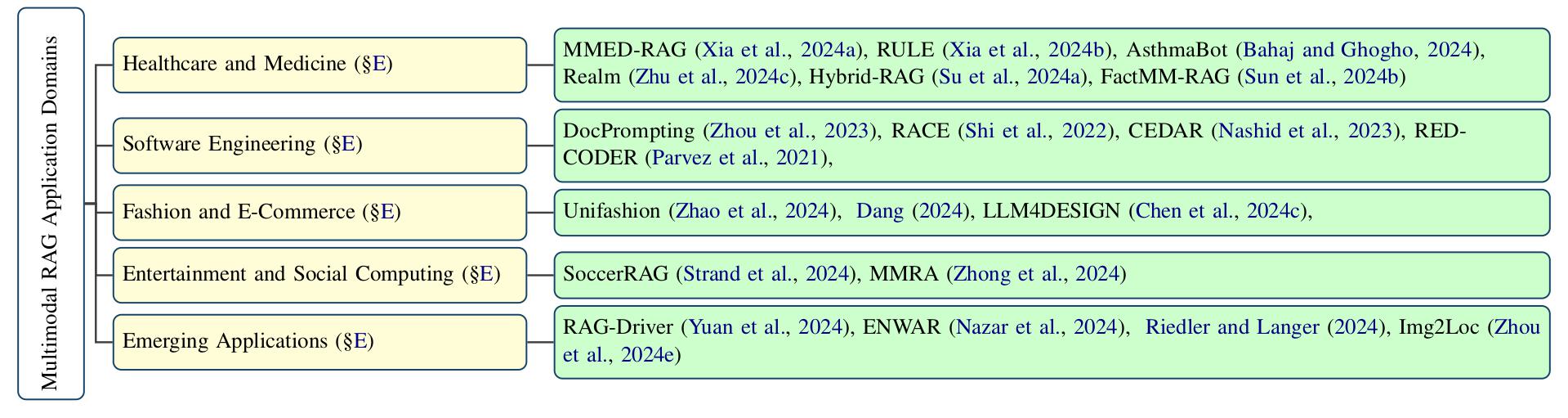
abstract = "Large Language Models (LLMs) suffer from hallucinations and outdated knowledge due to their reliance on static training data. Retrieval-Augmented Generation (RAG) mitigates these issues by integrating external dynamic information for improved factual grounding. With advances in multimodal learning, Multimodal RAG extends this approach by incorporating multiple modalities such as text, images, audio, and video to enhance the generated outputs. However, cross-modal alignment and reasoning introduce unique challenges beyond those in unimodal RAG. This survey offers a structured and comprehensive analysis of Multimodal RAG systems, covering datasets, benchmarks, metrics, evaluation, methodologies, and innovations in retrieval, fusion, augmentation, and generation. We review training strategies, robustness enhancements, loss functions, and agent-based approaches, while also exploring the diverse Multimodal RAG scenarios. In addition, we outline open challenges and future directions to guide research in this evolving field. This survey lays the foundation for developing more capable and reliable AI systems that effectively leverage multimodal dynamic external knowledge bases. All resources are publicly available at https://github.com/llm-lab-org/Multimodal-RAG-Survey."
}